Overview
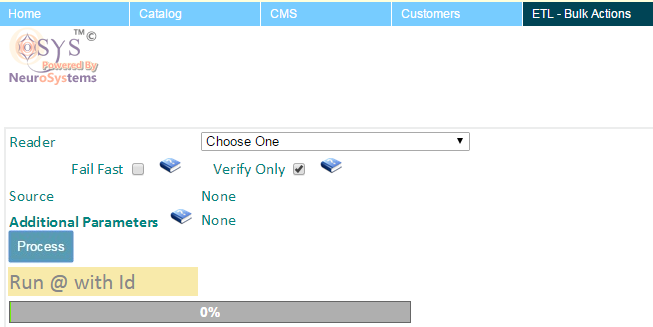
ETL is a tool that allows the admin to perform bulk or time consuming operations that may affect multiple records in one go.
There are unlimited examples of this, but for an introduction the following to name a few:
- Bulk import Data from Excel : The platform can directly import data from Excel files, in a format the business feels comfortable with. The platform does not force any type of format onto the business and can be customized to accept any column field mapping structure. However once a format is decided, then the admin is expected to provide data in the same format each time.
- Image resize for multiple products : Websites demand optimized images for various pages. It is manually very difficult to sit an optimize each image. This entire process can be automated.
- Automated image association using File Name to the product : For example we can have a scheme that relates the SKU Code as a file name to the product. The shcemes can get very complex. Another example maybe, where the same model product is available in different sizes but the image is the same for them all.
- 3rd Party Integrations Like CDN Integration or Bulk import from another system. For example Amazon CDN Integration for CMS
- Any other process that takes time (asynchronous)
- Reload Shipping rules/logic on the fly without restarting the system
... etc.
The ETL Flow
While the ETL processes can be many and vary from project to project. They all follow the same flow.
- Select the Reader :
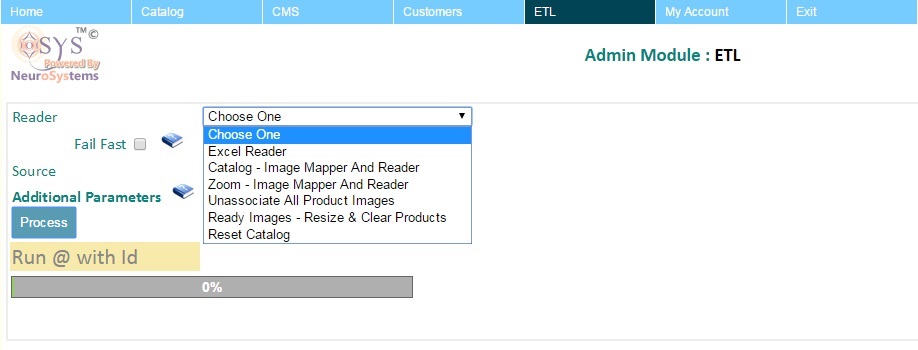
Each type of ETL process has a READER associated with it. For example Excel Reader or an Image Reader etc. The admin should pick the ETL Process for the job they want to conduct.
- Select the Mode :
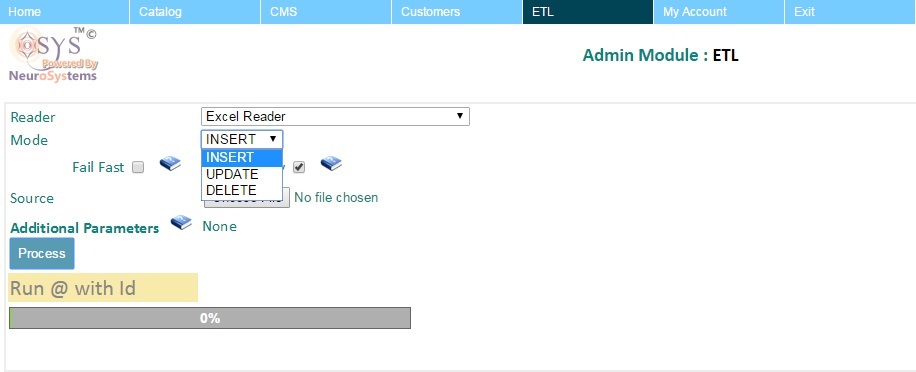
Depending on the type of job/reader, the admin may want to perform one of the operations mentioned below.
- INSERT : Used when you want to only add new Products or Data into the system. If the data contains existing items, it will compain but ignore those records. So if you have a Excel with old and new data, and are worried that the OLD data should be ignored then INSERT is the mode to choose.
- UPDATE : Will only consider existing records from the input data and will ignore any new records the process encounters.
- INSERT + UPDATE : When not sure and your data is a monolithic file of old and new records, the suggested order is to do an ETL first on INSERT mode and then in UPDATE mode.
- DELETE : To clean/delete multiple specific records in Bulk.
Note: When you delete a product it only deletes the product from the database, it does not delete its images. That is not necessary, however over time one may want to clean it t osave disk space and improve performance using FTP directly.
Conditional Modes : On selecting a reader, the ETL admin may further influence what type of operations are available. For example, in an Image resize option there is no requirement for any Mode to be specified and hence you will not be give any choice to select any Mode.
- Choose to verify first : If there is any input data like in the case of Excel file, one may want to check the file for any faults in its format before proceeding with the actual update. If the Checkbox is selected, it will only verify the file but not commit any of its data to the system. For any Reader if you want the system to make updates please ensure the verify option is NOT SELECTED, once yo uare confident that the data is ready.
- Upload File / Provide additional parameters : Depending on the nature of the Reader you may have to choose a File to upload or pass additional data. This depends on the Reader selected.
- Process : Once all the other options have been selected, simply press the Process button. This will start a progress bar from 0% to 100%. On clicking please note the Process ID and date/time mentioned. It looks like this: Run @ 05-Jul-2015 11:02:31 PM with Id 626957.
If there is a problem support can identify the process if you communicate the same to them. You should also get an email about the same details that the process has started on your registered admin account email address (can check on Systems or Home page what the email ID is).
- Post Process :
- PASS : If the process goes to 100% without any error, you will also get an email stating the process as successful. The subject of the email will mention the word ETL or process or both
- FAIL : if there is a failure in the process, it will show the reasons for failure. You can try to fix it or report it to the technical person incase you are not able to understand or fix the issue yourself.
Be sure to communicate the Process Id or forward the email that contains these details.
- Hang State : Sometimes a process may seem its stuck or taking a long time. If you have got an email then it means it just the user interface that has got disconnected. If not, treat it as a FAIL case and follow the advice in FAIL.
Excel Reader
The excel reader is used to import data in bulk from an Excel file from your local computer. You can choose any of the modes mentioned.
Please also note, that the excel reader can be used for other purposes (if they apply to your application); like loading COD pin-code and cash limit data etc and not just products.
If the reader encounters an error, it will either be a WARNING or a CRITICAL ERROR. A warning will indicate something wrong in a particular row but it will carry on. For example, a column where Price was to be a number but instead you mentioned the SKU code text.
Also note the numbering starts from 0. So if it complains there is a probblem on row 5 column 6, in human terms thats the 6th row and 7th column.
Image Mapper & Reader
Map images to their entities
Once the images are ready, the system copies the optimized versions to various folders that the website recognizes/accesses. Now, we are ready to map the image(s) to their respective products or entities.
For this you must ensure the Image file name matches the convention given for your application. If the system finds any images that do not map to any product, it will warn you but that is not considered as a critical problem and hence it can continue to map the other images.
You must ensure though that all the products are updated in the System before you run this. This is because the ETL process needs to know the SKU or the product identifier to map it to the image. If you have not INSERTED the record or product before, then the system has no way of knowing the image belongs to which process.
Ready Images
This type of reader, goes through all the images in the FTP upload folder and starts compressing them one by one if they are not already compressed. For this reason this reader may take time to complete. Of all the readers, this is the slowest.
Clean Redundant images & Unassociate Readers
Clean and remove any existing mappings between images and their products or entities
This is optional, and only removes any product associated with their images. This is useful if you want to simply clean or remove any product images from existing products.
Clean does not always imply the file or image itself will be deleted, it merely means that the association between the images and their entities are broken. By convention "Clean Mapping" or "Unassociate" means to simply break the relation, while "Clean Redundant" means the reader actually will delete the file. You can check the Reader description or check with your administrator to know which does what.
Clean Dirty images
Images and files may be copied and optimized, leaving them in multiple folders. A Dirty image, is one that is left over in an intermediate folder but no longer exists in the source folder. Cleaning dirty images hence implies, this action will clear the derivate folder completely, so that all images in source are the ones to be considered for the target.
Lets assume the following structure exists:
An UPLOADS folder
(For User to organize their images the way they like) : site-content/catalog/original/uploads,
A STAGING FOLDER
(For the System to flatten any user defined hierarchy and remove duplicate files with same names across user folders) : site-content/catalog/original/all
A TARGET folder
(with final optimized images for the site)
Images are taken from the UPLOADS folder and flattened into the STAGING folder. Any optimization process then takes images from the STAGING folder into TARGET folder. This gives 2 benifits. (1) If the UPLOADS folder is cleared, the STAGING retains old images. (2) Weed out duplicates.
Sometimes, however the STAGING folders may cause an old image with the same name to persist. Using this action will clear it.
Reset Catalog
Empty the entire catalog data, except categories. All products will be deleted, leaving only the caqtegory skeleton.
Avoid this, unless you really know what you are doing!
Other readers
There can be more types of readers/processes. Those will be for more advanced cases and be available in the documentation of various other modules that provide the reader for bulk operatiosn concerning them. Example: Content CDN, Scripting etc.
Catalog update steps
A typical Bulk update on your catalog based site will include the following steps:
- Excel Reader to import the data for your products
- Ready Images to ensure images are ready (if there are any new images else skip this step)
- Image mappers - Catalog, Zoom etc to map images (if you have performed any image related step then perform this)
Troubleshooting
Note on Post ETL issues : There can be issues related to you not being able to see changes post ETL process. Like you could not see the updates reflected on the site after making them or images are not showing up etc. Those issues are not really part of the ETL process and you can read more about them
here.
While processing any tabular data like Excel sheet or file; the ETL process will clearly list any errors in the process.
- You can always check the ROW and COLUMN index to know where the error came from. This shoudl clue you to the origin of the problem if not the reason.
- ROW and COLUMN index numbering starts from 0 (zero). So [3,4] actually means the 4th row and 5th column in the Sheet.
- Some cases the column index may show up as -1. This means there was a problem in deriving some data. For example lets assume a category CODE was provided. The category CODE in the Excel maybe correct, but due to some issue in the system it was not able to find the category related to that code. As you can see some errors can be a result of intermediate problems and the system may prefer not to blame any particular column for it (hence -1). Intermediate derivations use Mappers so it will also mention a mapper name. The mapper name gives a clue to what information it was trying to derive. Example: parentId means, it was trying to determing the parent category of the product.
- Null is a technical term for 'Not Found' or 'Does not exist'
Additionally, you should copy the
Process Id and time on the screen. You will also get an email for the ETL process that you can forward to the admin/developer if you are not able to understand the reason for any particular error.
Common errors
Get an error like the following when uploading an Excel Sheet or File:
ProcessId:725521; Critical error, aborting process : Problem with file, technical details - org.apache.poi.poifs.filesystem.OfficeXmlFileException: The supplied data appears to be in the Office 2007+ XML. You are calling the part of POI that deals with OLE2 Office Documents. You need to call a different part of POI to process this data (eg XSSF instead of HSSF)
Excel itself can have various file formats in different versions. Like XLS, XLSX etc. Within them there maybe variations depending on the type of Office used, some of them the software may not support yet or maybe the ETL reader is configured to work with one and not the other. Either way, to work around this, simply
Save As XLS format and try again with the new file.
Duplicate Records
Get an error like the follwing when uploading an Excel Sheet or File:
Example: Duplicate entry 'Tori Grey Napkin-NR15-NAP-28A' for key 'name'
This means the record already exists and you are running in INSERT mode while this should be run in UPDATE mode. You can safely ignore this if you intend to use a Sheet for both INSERTs and Updates.
New Records
Get an error like the follwing when uploading an Excel Sheet or File:
Example: Rejected attempt to modify Tori Grey Napkin-NR15-NAP-28AXXX when it does not even exist in the system. Try to INSERT the record before you attempt to UPDATE it!;
This means the record does not exist but the ETL process was in UPDATE mode trying to update it. You can safely ignore this if you intend to use a Sheet for both INSERTs and Updates.
Invalid Lookup or Category
Some errors are a result where the error will mention the words parentId or category. You have specified an invalid category or a category code that does not exist or is not correctly mapped in the system. You need to fix your data and mantion the correct category name or code.




